
Every time a new client asks us for a price or proposal, we face the age-old estimation paradox; do we spend a lot of time on this scoping exercise, making sure we get all the details right, and risk wasting that time if we don’t win the work? Or do we copy an old proposal, make a few tweaks, cross our fingers, and hope the project doesn’t end up being a bigger dumpster fire than Florida during a pandemic. (Sorry, Carl!)
The truth is, those options don’t have to be mutually exclusive. With the right processes and feedback loops in our agency, we can get to a place where reliable estimation isn’t all-consuming.
In this two-part series, we’re going to break down how we’ve made our estimation process both accurate and efficient by leveraging the data and insights we were already creating every day, and how you can do it too.
The Anatomy of a Consistently Accurate Estimation Process
The objective of the estimation process is to close the gap between the assumptions we make about how much time, money or effort it will take to deliver a promised outcome to a client and reality.
The common misconception is that those gaps are a result of us not being good enough at predicting outcomes. However, our experience has been that the estimation process is often set up for failure because it’s trying to predict processes that aren’t well defined, and therefore aren’t very predictable. We’ve used a process we’ve coined “The Agency Profitability Flywheel” to install feedback loops that connect the estimation process to the delivery process in order to systematically close these gaps over time, and engineer accuracy into our operational model my making the model itself more predictable:

In part one of this series, we’ll cover the first two steps of this framework:
Defining Estimation Frameworks
Installing Quantitative Feedback Loops (Time & Cost Tracking)
The key outcome from installing these first two steps will be the ability to generate estimates quickly without compromising on accuracy.
Step One: Defining Estimation Frameworks
The first step to installing our feedback loop is to formalize the estimation framework. A standardized system for estimating work is fundamental to a scalable service business.
When it comes to estimation, there are many ways to “skin the cat”. At the end of the day, what is most important about our estimation framework is that it clearly defines measurable assumptions about the riskiest parts of our agency’s operational model.
The simple way to think about this is by answering the following question:
What are the assumptions that, if proven inaccurate, could have the largest impact on our profits and people? Would it force us to absorb costs or work a lot of overtime?
Generally, the answer to this question ties back to two things:
1. Scoping Metric
Scoping Metrics determines the relationship between the inputs we collect during the discovery or sales process and our conscious or unconscious formula for how it impacts the scope of an engagement.
To define your “scoping metric” try filling in the blank in this sentence:
The more _____, the more effort it will take to deliver on an engagement.
Usually, the answer is something like:
“The more…
Budget the client has
Webpages the client needs
Blog posts the client wants
Custom widgets the client needs
etc.
For example: “The more webpages a client needs, the more effort it will take...”

The end goal of this process is to get to a place where we can articulate the formula for how our estimation inputs impact the outputs like:
“On average, every additional webpage adds 5 hours of design, 4 hours of development and 1 hour of project management time to the project scope.”
Collecting data on the relationship between these scoping metrics and how they impact effort is one of the quickest ways to start speeding up the estimation process while also making it more accurate.
2. Operational Model Complexity
It’s extremely important to choose the right level of granularity in our estimation framework. If we’re too specific and granular, it can be extremely expensive, time-consuming or burdensome to collect the data necessary to measure the accuracy of these estimates.
If we go too broad, we risk not being able to answer important questions that pertain to risky aspects of our operational model. Balancing tradeoffs between complexity and overhead is key to landing on the right framework.
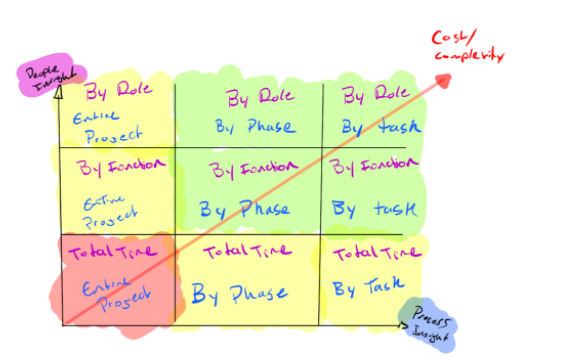
The best way to do this is to reverse engineer the way you investigate projects that go way over budget today. What is the sequence of questions you ask yourself and your team? Do you focus on the phase or step in the process that went awry, or are you more focussed on people or departments?
The answer to these questions should help you identify what cross section of insight is necessary for you to get enough insight to support your investigation process and facilitate conversations with the team.
This brings us to the next step in this process, which is installing the systems necessary to make measuring the accuracy of our assumptions effortless and timely.
Step Two: Installing Quantitative Feedback Loops (Time & Cost Tracking)
The next step in the process of creating accurate estimates is to ensure we have the proper mechanisms in place to assess if our assumptions about our projects hold up in the real world. This essentially places data points on our relationship graph, and informs the reliability of our relationship line. The more data we can collect, the more reliable that line becomes.
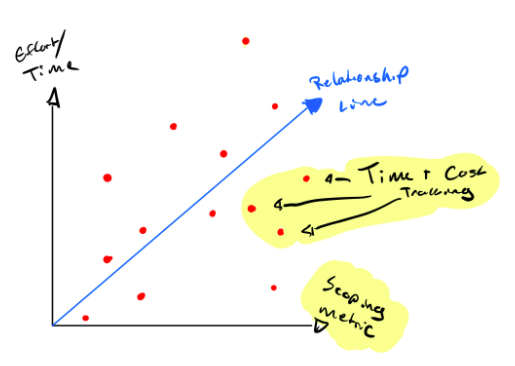
While this sounds obvious and easy, unfortunately, it’s often not as straightforward as one might hope.
There are two common conflicts that can derail this essential step in the feedback loop and make reconciling our data more challenging than it needs to be:
Clashing project management and operational structures
The first common hiccup at this stage has to do with a conflict between the way the operations team creates estimates for projects and the way the project management (PM) team wants to manage them.
The most common example of this I see is when estimates are broken down by function or role:
“X hours of Development, XX hours of Design, XX hours of Project Management, etc.”
Whereas the project management philosophy is more aligned with tasks:
”X hours on the content outline, XX hours on the wireframes, XX hours on Q/A, etc.”
This often becomes problematic when the tools agencies use to track time (be it a time-tracking tool or a resource planning tool) are integrated into the project management tool.
Often in these cases, the time-tracking data will take on whatever structure is laid out in the time tracking tool, regardless of whether the data maps cleanly back to the structure of the estimate.
This becomes especially problematic when naming conventions in the project management tools aren’t horizontally consistent. For example, tasks might be uniquely named on different client projects, despite being the same (or similar) tasks.
The end result is a data set that is unable to offer horizontal insights and is notoriously difficult to reconcile against the assumptions that were made in the estimate, or answer questions about things like “how long does this part take us on average across our last 20 websites?”
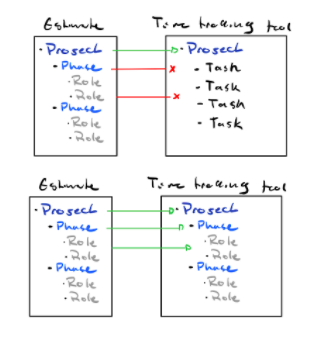
The important action item at this step is to audit whatever mechanisms our agency is using to measure the time and cost investments on projects to ensure the data is structured in a way that aligns to our estimate. Often the best way to do this is to use a completely separate tool that is not fully integrated into the project management suite, like Harvest or Toggl for time tracking, or QuickBooks or FreshBooks for accounting
Completely separate tools often ensure that the structure of the data can be defined independently of the project management tool, allowing the operations team and the project management team to operate without compromises.
The two most important elements of tracking time or cost data are:
Compliance
Honesty
In short, we want to make sure that we’re getting as complete and consistent a flow of data into our systems as possible, and ensure that the way we capture that data is aligned with the incentive to input the truth, even when the truth is things aren’t going as planned.
As long as the level of detail and operational overhead required to align time-tracking data to the estimate isn’t overly burdensome for the team responsible for capturing that data, and doesn’t cause prohibitive concessions for the way the PM team wants to structure work in their environment, the time/cost tracking tooling should be able to produce good outcomes.
Once the tooling for the feedback loop has been installed, it should be very straightforward to pull a report detailing the estimated and actual results of our projects on a repeatable cadence and use it to drive conversations in part three of our framework.
With this qualitative feedback loop in place, you should be empowered to start building reliable relationships between your scoping metrics and effort that are based on real data and estimate works without compromising on accuracy.
What’s Next in Part Two?
Stay tuned for part two of this series, where we’ll talk about how to leverage the reports and data we’ve created in part one to facilitate conversations with our team and surface opportunities for process improvements. These process improvements will help us improve the accuracy of our estimates over time, by normalizing the distribution of the data points on our relationship graph.
This is a guest article from a member of the Bureau of Digital community. We're always looking for good tips and lessons, if you're interested in contributing please email smith@bureauofdigital.com.